
数据收集方法大揭秘:如何高效获取所需数据?
高效<...获取<......需数据是现代社会中一个至关重要的技能,无论是在商业分析、科学研究还是日常决策中,以下是一些高效获取数据的方法:
自动化抓取:网站爬虫是一种自动化程序,能够自动访问目标网站并提取所需信息,它通过发送HTTP请求、解析HTML页面并保存信息来实现数据的自动采集。
应用场景广泛:网站爬虫可以应用于数据技术分析、信息聚合和网络安全等多个领域,通过爬取互联网上的数据进行研究和分析,为商业决策提供支持。
遵守法规和协议:在使用网站爬虫时,需要注意遵守相关法律法规,尊重隐私和版权,避免对目标网站造成过大的负担。
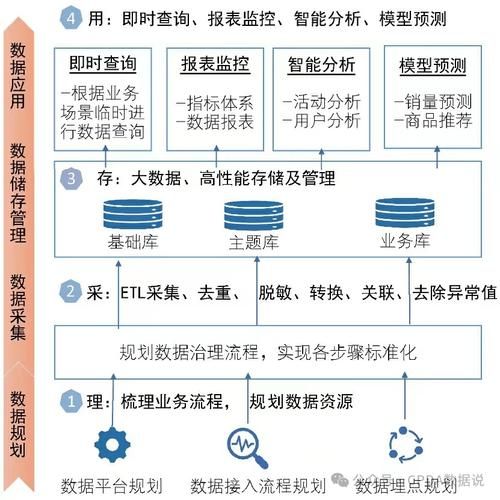
关键词搜索:搜索引擎是最常用的数据获取工具之一,通过使用精准的关键词,可以快速找到所需的新闻、论坛议题和专业知识。
高级搜索技巧:掌握搜索引擎的高级功能,如使用引号进行精确匹配、使用减号排除特定词汇等,可以提高搜索效率。
多平台搜索:除了谷歌,还可以使用其他搜索引擎如Bing和Yahoo,以获得更全面的结果。
3、访问数据库
专业数据库:许多公司和机构维护着专业的数据库,这些数据库包含大量经过审核和验证的数据,质量较高。
开放数据源:一些公共组织或机构发布的开放数据源,如世界银行和联合国的数据门户,提供免费且高质量的数据。
技术要求:使用数据库可能需要一定的技术能力,特别是涉及到复杂的查询语言和数据模型。
实时数据获取:社交媒体平台如TwiTTer和Facebook可以提供有关特定事件或话题的实时数据。
专业交流:LinkedIn和gitHub等专业社交媒体则可以提供行业或领域内的信息和数据。
数据筛选:社交媒体上的信息可能存在误导或虚假情况,需要经过处理和筛选。
自动化采集:大数据抓取工具能够自动化地从目标网站中提取所需的信息,并将其转换为结构化的数据格式。
应用场景多样:适用于市场调研、竞品分析、舆情监测等领域,通过抓取竞争对手的产品信息和销售数据来分析市场趋势。
工具选择:根据具体需求选择合适的工具,如网页抓取工具用于静态网页信息的采集,数据挖掘工具用于大规模数据分析。
直接获取数据:许多网站和服务提供API接口,通过调用这些接口可以直接获取所需数据。
定制化数据:API接口通常支持定制化的数据请求,可以根据具体需求获取特定的数据字段。
高效稳定:api接口调用方式高效且稳定,适合需要频繁获取数据的场景。
7、RSS订阅
持续更新:RSS订阅可以帮助用户持续获取更新的信息,适用于需要跟踪特定主题或网站的情况。
多平台支持:可以使用Reeder和Kindle4rss等工具在不同平台上进行RSS订阅。
系统化处理:对于科研单位或系统性的信息搜集需求,可以使用易海聚等信息整合方案,系统化地模拟信息收集、整理和归类过程。
智能分析:加入智能分析和算法,如智能聚类和标签提取,让信息来得更加简单直观。
提高效率:这种系统化的处理方式可以大大提高数据收集和整理的效率。
数据清洗和预处理:在获取到数据后,需要进行清洗和预处理,以确保数据的准确性和完整性,这一步可以使用Python中的pandas库等工具进行处理。
数据可视化:在数据分析阶段,可以使用matplotlib、seaborn等库进行数据可视化展示,帮助更好地理解和解释数据。
法律法规遵守:在数据收集过程中,必须遵守相关的法律法规,确保不侵犯他人隐私和知识产权。
反爬虫机制应对:有些网站会设置反爬虫机制,可以通过设置代理IP和使用Tor等工具来隐藏真实IP,或者通过OCR技术识别验证码来应对。
高效获取所需数据需要结合多种方法和工具,根据具体的需求和场景选择合适的方式,注意数据的准确性、合法性和隐私保护,才能确保数据收集工作的顺利进行。
本文系作者个人观点,不代表本站立场,转载请注明出处!如有侵权,有联系邮箱845981614@qq.com处理!















